
In my last post, I have written about ACT and how it helps robots learn specific tasks, like folding a shirt or putting a cup in a sink. But there was a catch: ACT is a specialist. And from the rise of LLM’s we now know that a specialist cannot compete in this age. We need a generalist policy.
Since we already know that LLMs indeed work, why don’t we use it for robotics too? Let’s think step by step.
– To control a robot we need to give not only text, but also visuals. That means we should use a VLM (Vision Language model). Now we have a model that can both understand my prompt and the image that we sent.
– But, when we give it a prompt and an image, VLM’s response is text. It says: “I see a blue coffee cup on the table.” Or if we are lucky, it might say: “Move the end-effector 10cm forward.” Clearly we need to convert tokens into actions somehow. We can use an Action Head to convert the output into a real action. And that gives us the last step: VLM + A = VLA
As you can see, it was no brainer to start from LLMs and end up with the basic architecture of VLAs. Before we dive deep into this method, let’s talk about how people generally get success from VLAs.
How people generally train VLAs
1. Companies like Physical intelligence use pre-trained VLMs (like PaliGemma). These models already have some level of understanding of our physical world.
2. Then using the VLM + Action Head architecture, they train a base model (like pi0.5) with a variety of data. Different robots, real world data, simulation data… Now, this model knows how to map a command and input image into an action sequence.
3. Lastly, depending on the use-case and the robot, the base model is fine-tuned on the domain specific data. For example if you are using SO100 Arm and you want the robot to clean up your desk, you can record some episodes and fine-tune pi0.5. Crazy times!
Let’s dissect some of the VLAs from pi
Physical Intelligence started with pi0, explained in their first blog post published online.
It uses the same structure that I have mentioned in the previous section. They fine-tune the PaliGemma VLM (a tiny 3B model!) with Open X-Embodiment Dataset, and their own dataset from 8 different manipulators. Now the VLM not only understands our incredibly rich, colorful and fun world, but with fine tuning it also knows how to be a robot doing incredibly mundane tasks. I bet PaliGemma wasn’t expecting that shift…
For the action head, they use a variant of diffusion models. You may have heard of diffusion in image generation, where the model tries to denoise a gaussian noise step-by-step to reconstruct a nice output. If we apply this same structure to actions, instead of pixels it looks like the following video.

It also solves the multimodality problem of robotics that I have mentioned in the previous blog. But Physical Intelligence didn’t stop there and used a variant of diffusion model called flow matching. Instead of predicting the denoised output at each step, the model predicts a vector field that tells it which direction to move at each point along a (mostly straight) path from noise to action. Because the path is straighter than a typical diffusion trajectory, you need far fewer steps to get there (which is exactly what you need when you’re outputting actions 50 times a second).
pi0.5
If you read “Thinking, Fast and Slow” by Daniel Kahneman you should be familiar with System 1 and System 2 modes of thought. System 1 is the instinctive fast mode and System 2 is slower and logical thinking processes. pi0 was a System 1 VLA. It can place ham inside a bread. But it can’t make a full sandwich from a single prompt.
With pi0.5, we are introduced with an architecture that can perform complex actions.
When you ask the robot a subtle prompt that needs multistep actions (for example “Put electronics on the floor to the box”), the VLM thinks about the high-level prompt (“There are multiple electronics boards in the floor, there is also a battery. I also see cables. Other items I see are not electronic related so no need to move them”). Then it predicts the subtasks (pick up the board, put it in the bin, etc…)
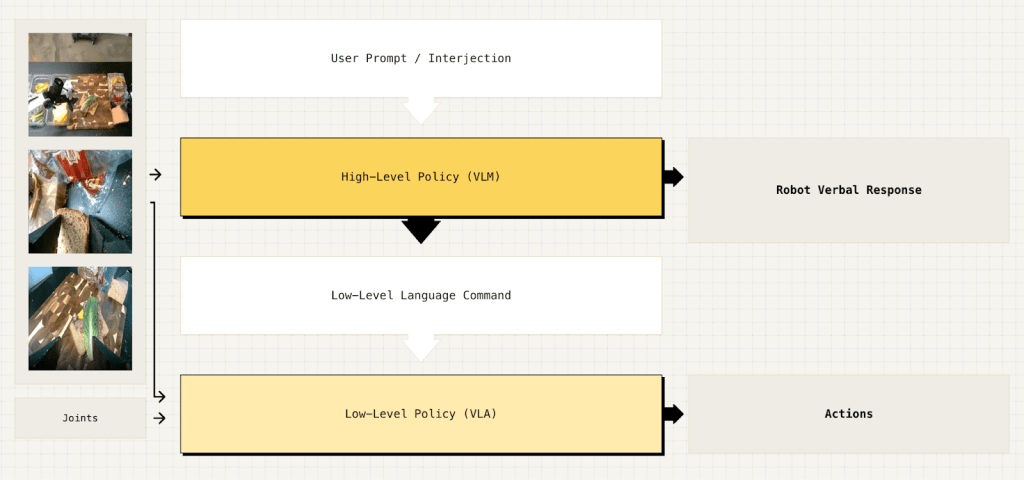
There is also an interesting method they introduce which is called Knowledge Insulation (KI). Before we get into this, let’s talk about a problem.
Action head makes the VLM dumber
That poor VLM was trained for understanding the text prompts and interpreting images. When we attach the action head to the VLM backbone, fine-tuning it results in an unwanted situation where the model is worse at interpreting the text input. As we finetune it, even though it becomes a better pilot when it comes to moving its joints, its “intellectual” side weakens. Physical intelligence shows this with an example where the robot is instructed to put the spoon into the dish container but instead it grasps the trash. Yes, you successfully grasped the trash but that was not what I asked for!
KI Architecture
What would happen if we get the input from VLM to the action expert, but do not modify weights of the VLM based on the action expert during training?
In the pi0.5+ KI architecture, the VLM’s job is to take images, prompts, and proprioceptive data to predict FAST action tokens. This is a “representation learning” task and it forces the VLM brain to understand the logic of the robot’s world.
The Action Expert’s job is to turn that understanding into continuous motion. But it doesn’t actually wait for the VLM to spit out tokens; instead, it sits inside the same shared attention layers as the VLM and reads its hidden states (its raw internal thoughts) directly, with a masking trick that lets information flow one way (backbone → action expert) but blocks gradients from flowing back during training.
Turns out this is not only more reliable than the previous method, but also faster to train.
pi*0.6
I have always wondered how a robot can handle a messy situation, especially one that it caused itself.
For example, what would happen if it dropped a cup on the ground? Would it look down and pick it up? Probably not, because the “expert” who created the dataset never demonstrated that behavior.
Following this logic, we can conclude that in robotic imitation learning, any error that occurs during inference will accumulate. As these errors compound, the robot’s inputs drift further away from the training distribution. It’s like a very nervous person. Once they make a small mistake, they become more anxious, which leads to even more mistakes.
To fix this issue, Physical Intelligence developed a method called RECAP.
In this method they,
- Run the model on tasks and label the task outcome for each episode (0: fail, 1: success), also manually intervene and fix the actions by teleoperation.
- Create a value function which calculates “expected time to task completion” normalized from -1 to 0.
- Retrain the VLA with this value function
The first part is easy to understand, overall it’s just model inference and some manual labeling. But how are these labels used in the value function?
If you read my Teaching my dog to walk (in simulation) blog post, I defined a reward function where, anytime the dog moves forward, it gets a point, and anytime it falls, it is punished. They use a similar reward function, where each step yields higher cumulative reward (as we get closer to the goal), and if the task fails, we receive a large punishment.
Now this trained value function predicts the number of steps needed to finish the task. For example, in the example below we start with a low probability (remember that the predictions are normalized between -1 and 0) and gradually the probability of finishing the task based on the input increases. But right around the 100. step we see that progress is lost because of a mistake, later it tries to recover and achieves this.
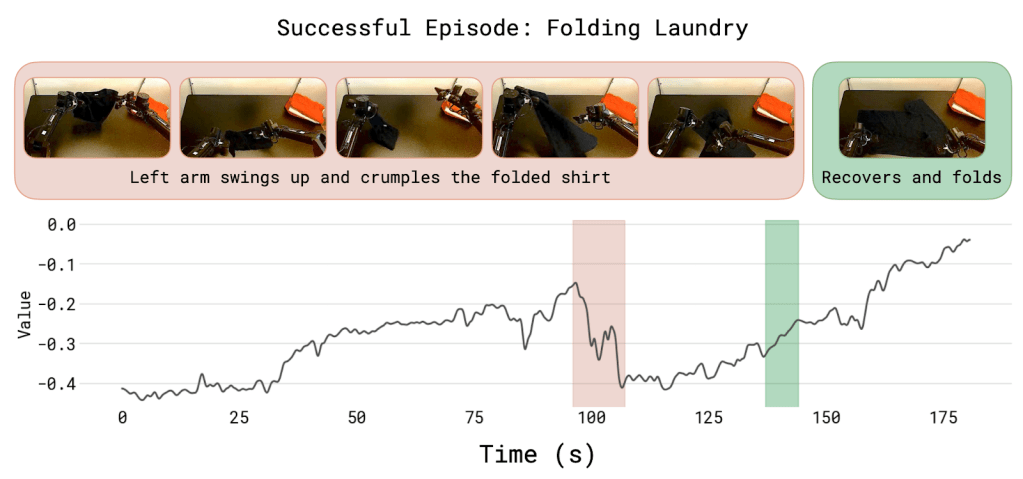
With this value function we can see where the robot makes progress and where it makes mistakes and we can do it by only looking at a single graph! Now we can use this function to retrain the VLA.
In reinforcement learning, there is a thing called “advantage” and it is essentially the difference between reality and expectation. The value function looks at the current image and prompt and says “based on what i have seen, we are about 50 steps from finishing this task” (expectation), and if the episode terminates after 90 steps it means the action has no positive advantage.
Now with this info, they switch to prompt engineering and add “Advantage: positive” or “Advantage: negative” to every prompt. Now instead of deleting bad actions, they feed them to the VLA with a label.
After that what would you do in inference? If you like to see a disaster you would add “Advantage: negative” to every prompt, but since the goal is success, in inference they add “Advantage: positive” to every prompt. This is like giving orders to somebody but also adding “please do it well” in every step, which is hilarious but it works!
Does everybody agree on VLA’s?
While the VLA architecture is the dominant trend now, it is not the only way to build a robot brain. You might have heard of world models. World models focus on predicting the future state of the environment to simulate and plan actions internally. This means instead of just reacting, a world model learns physics and causality. Is it better to predict the world before acting, or can we merge them by using a world model as the predictive backbone for a VLA? Maybe we can explore these ideas in the next blogs.
Thank you for reading!

Yorum bırakın